sata boot support on this platform is experimental
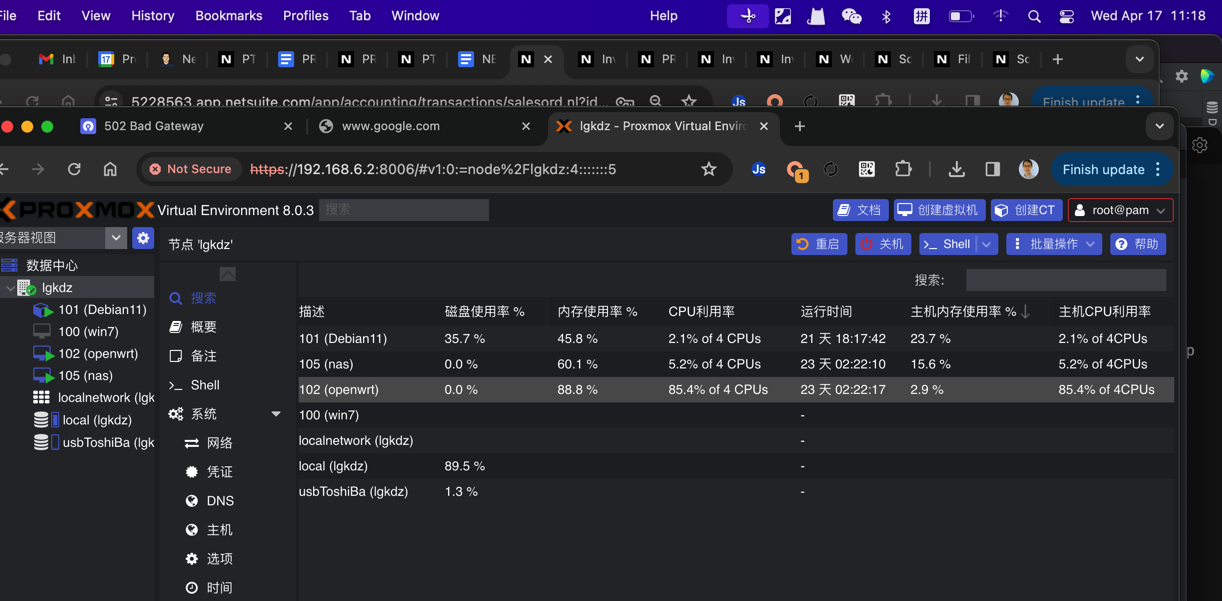
关闭虚拟机,后尝试重启,pve错误:
WARN: no efidisk configured! Using temporary efivars disk. Warning: unable to close filehandle GEN7208 properly: No space left on device at /usr/share/perl5/PVE/Tools.pm line 254. TASK ERROR: unable to write ‘/tmp/105-ovmf.fd.tmp.29425’ - No space left on device
#PVE的情况 root@lgkdz:/# systemctl status pveproxy.service ● pveproxy.service - PVE API Proxy Server Loaded: loaded (/lib/systemd/system/pveproxy.service; enabled; preset: enabled) Active: active (running) since Sun 2023-11-19 19:25:04 CST; 1 month 9 days ago Process: 989 ExecStartPre=/usr/bin/pvecm updatecerts --silent (code=exited, status=0/SUCCESS) Process: 991 ExecStart=/usr/bin/pveproxy start (code=exited, status=0/SUCCESS) Process: 56738 ExecReload=/usr/bin/pveproxy restart (code=exited, status=0/SUCCESS) Main PID: 993 (pveproxy) Tasks: 4 Memory: 162.3M CPU: 2h 15min 3.182s CGroup: /system.slice/pveproxy.service ├─ 993 pveproxy ├─12296 "pveproxy worker" ├─12300 "pveproxy worker" └─12302 "pveproxy worker" Dec 29 10:17:46 lgkdz pveproxy[993]: worker 12296 started Dec 29 10:17:49 lgkdz pveproxy[12280]: worker exit Dec 29 10:17:49 lgkdz pveproxy[993]: worker 12280 finished Dec 29 10:17:49 lgkdz pveproxy[993]: starting 1 worker(s) Dec 29 10:17:49 lgkdz pveproxy[993]: worker 12300 started Dec 29 10:17:49 lgkdz pveproxy[993]: worker 12295 finished Dec 29 10:17:49 lgkdz pveproxy[993]: starting 1 worker(s) Dec 29 10:17:49 lgkdz pveproxy[993]: worker 12302 started Dec 29 10:17:49 lgkdz pveproxy[12300]: Warning: unable to close filehandle GEN5 properly: No space left on device at /usr/share/p erl5/PVE/APIServer/AnyEvent.pm line 1901. Dec 29 10:17:49 lgkdz pveproxy[12300]: error writing access log
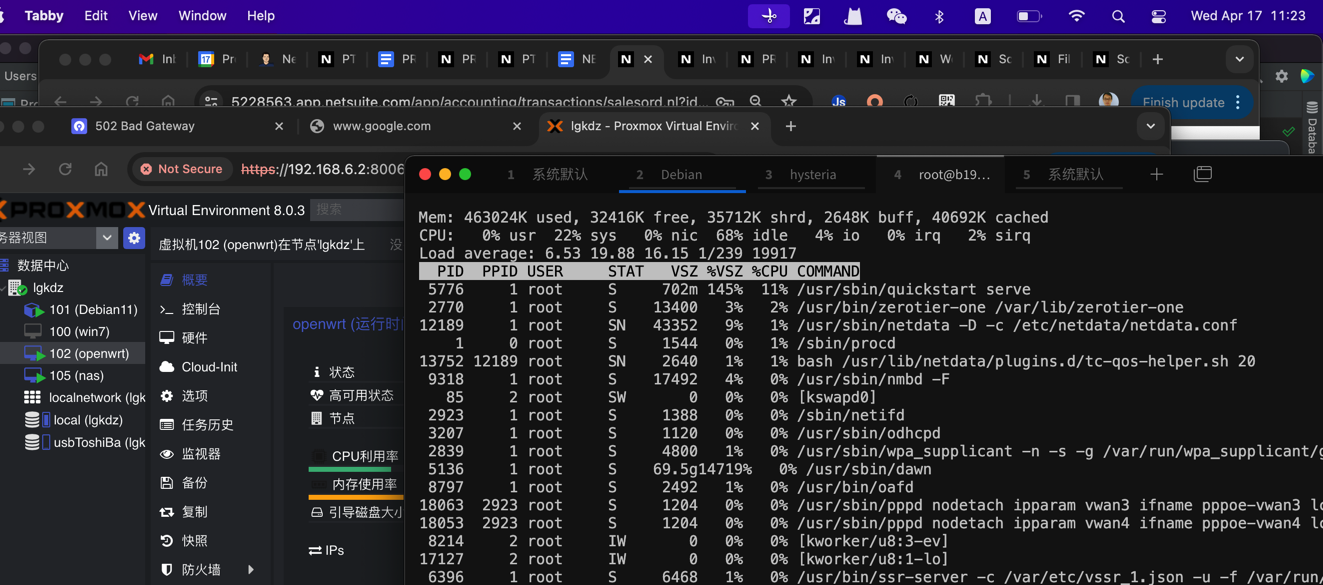
加载下来看看,Kingchuxing里面的500G的数据情况:
1
mount /dev/sda5 /mnt/sda5
清理+管理Linux日志
1 2
rm -rf /log/*.gz rm -rf /var/log/*.1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
journalctl --disk-usage # 查看占用的磁盘 Archived and active journals take up 2.5G in the file system. # 设置占用的磁盘空间,日志量大于这些后自动删除旧的 journalctl --vacuum-size=512M
Vacuuming done, freed 2.0G of archived journals from /var/log/journal/2afbdd1662c14f99a11ce27fcda8ab85. Vacuuming done, freed 0B of archived journals from /run/log/journal. # 2d之前的自动删除 journalctl --vacuum-time=2d #这一顿清理日志以后,硬盘空间: 98.33% (106.39 GiB的108.20 GiB)
在此尝试启动NAS
WARN: no efidisk configured! Using temporary efivars disk. TASK WARNINGS: 1
1 2 3 4 5
Debian的日志清理,维护 > journalctl --disk-usage # 查看占用的磁盘 Archived and active journals take up 104.0M in the file system.
1、find查找根下大于800M的文件
find / -size +800M -exec ls -lh {} ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
>root@lgkdz:/var/log# find / -size +800M -exec ls -lh {} \; -r-------- 1 root root 128T Nov 19 19:24 /proc/kcore find: ‘/proc/3193/task/3251/fd/34’: No such file or directory find: ‘/proc/3193/task/3251/fd/35’: No such file or directory find: ‘/proc/14759’: No such file or directory find: ‘/proc/14779’: No such file or directory find: ‘/proc/14780’: No such file or directory find: ‘/proc/14781/task/14781/fd/5’: No such file or directory find: ‘/proc/14781/task/14781/fdinfo/5’: No such file or directory find: ‘/proc/14781/fd/6’: No such file or directory find: ‘/proc/14781/fdinfo/6’: No such file or directory -rw-r--r-- 1 root root 1.3G Oct 14 20:50 /var/lib/vz/dump/vzdump-lxc-101-2023_10_14-20_48_21.tar.zst -rw-r----- 1 root root 51G Dec 25 09:46 /var/lib/vz/images/100/vm-100-disk-0.qcow2 -rw-r----- 1 root root 11G Dec 29 13:34 /var/lib/vz/images/102/vm-102-disk-0.qcow2 -rw-r----- 1 root root 101G Dec 29 13:34 /var/lib/vz/images/105/vm-105-disk-2.qcow2 -rw-r----- 1 root root 50G Dec 29 13:34 /var/lib/vz/images/101/vm-101-disk-0.raw -rw------- 1 root root 4.6G Nov 4 10:52 /core
1 2 3 4 5 6 7 8
> root@Debian11:~# find / -size +800M -exec ls -lh {} \; -rw-r----- 1 root root 1.2G Dec 29 13:43 /var/lib/docker/containers/a611cae746aa6c4b1e3bda308a7935180b79e0f684a75791910430989 1e2c979/a611cae746aa6c4b1e3bda308a7935180b79e0f684a757919104309891e2c979-json.log -r-------- 1 root root 128T Nov 19 19:26 /proc/kcore -r-------- 1 root root 128T Dec 17 09:32 /dev/.lxc/proc/kcore
检查异常大小的log文件 cd /var/lib/docker/containers/a611cae746aa6c4b1e3bda308a7935180b79e0f684a757919104309891e2c979
/dev/mapper/pve-root 就是pve卷组里的一个逻辑卷pve > root@lgkdz:/var/log# pvdisplay --- Physical volume --- PV Name /dev/sdb3 VG Name pve PV Size 118.24 GiB / not usable <3.32 MiB Allocatable yes (but full) PE Size 4.00 MiB Total PE 30269 Free PE 0 Allocated PE 30269 PV UUID jEzPvE-ELri-mvlq-5Jpi-s96g-a44F-SWWM4N > root@lgkdz:/var/log# vgdisplay --- Volume group --- VG Name pve System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 9 VG Access read/write VG Status resizable MAX LV 0 Cur LV 2 Open LV 2 Max PV 0 Cur PV 1 Act PV 1 VG Size <118.24 GiB PE Size 4.00 MiB Total PE 30269 Alloc PE / Size 30269 / <118.24 GiB Free PE / Size 0 / 0 VG UUID aBqMlz-dH1H-PEif-LGT5-khnl-oEXf-sMtWTc > root@lgkdz:/var/log# lvdisplay --- Logical volume --- LV Path /dev/pve/swap LV Name swap VG Name pve LV UUID Wl0zSQ-Rlkj-4TLc-yyuM-Ntg1-1T27-QK3KOg LV Write Access read/write LV Creation host, time proxmox, 2023-07-01 20:13:17 +0800 LV Status available # open 2 LV Size 8.00 GiB Current LE 2048 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:0 --- Logical volume --- LV Path /dev/pve/root LV Name root VG Name pve LV UUID dFYnFo-1PQw-3qUM-sR9V-2eqf-BKn8-yTASwe LV Write Access read/write LV Creation host, time proxmox, 2023-07-01 20:13:17 +0800 LV Status available # open 1 LV Size <110.24 GiB Current LE 28221 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:1
lsblk 查看所有存在的磁盘及分区(不管使用挂载是否)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
root@lgkdz:/var/log# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS loop0 7:0 0 50G 0 loop sda 8:0 0 476.9G 0 disk ├─sda1 8:1 0 8G 0 part ├─sda2 8:2 0 2G 0 part ├─sda3 8:3 0 1K 0 part └─sda5 8:5 0 466.7G 0 part sdb 8:16 0 119.2G 0 disk ├─sdb1 8:17 0 1007K 0 part ├─sdb2 8:18 0 1G 0 part /boot/efi └─sdb3 8:19 0 118.2G 0 part ├─pve-swap 253:0 0 8G 0 lvm [SWAP] └─pve-root 253:1 0 110.2G 0 lvm /
Matomo-DB | 2023-12-29 10:46:40+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' Matomo-DB | 2023-12-29 10:46:40+00:00 [Note] [Entrypoint]: Entrypoint script for MariaDB Server 1:11.2.2+mari a~ubu2204 started. Matomo-DB | 2023-12-29 10:46:40+00:00 [Note] [Entrypoint]: Initializing database files Matomo-DB | 2023-12-29 10:46:40 0 [Warning] Can't create test file '/var/lib/mysql/6be765c4a185.lower-test' ( Errcode: 13 "Permission denied") Matomo-DB | /usr/sbin/mariadbd: Can't change dir to '/var/lib/mysql/' (Errcode: 13 "Permission denied") Matomo-DB | 2023-12-29 10:46:40 0 [ERROR] Aborting Matomo-DB | Matomo-DB | Installation of system tables failed! Examine the logs in Matomo-DB | /var/lib/mysql/ for more information. Matomo-DB | Matomo-DB | The problem could be conflicting information in an external Matomo-DB | my.cnf files. You can ignore these by doing: Matomo-DB | Matomo-DB | shell> /usr/bin/mariadb-install-db --defaults-file=~/.my.cnf Matomo-DB | Matomo-DB | You can also try to start the mariadbd daemon with: Matomo-DB | Matomo-DB | shell> /usr/sbin/mariadbd --skip-grant-tables --general-log & Matomo-DB | Matomo-DB | and use the command line tool /usr/bin/mariadb Matomo-DB | to connect to the mysql database and look at the grant tables: Matomo-DB | Matomo-DB | shell> /usr/bin/mariadb -u root mysql Matomo-DB | MariaDB> show tables; Matomo-DB | Matomo-DB | Try '/usr/sbin/mariadbd --help' if you have problems with paths. Using Matomo-DB | --general-log gives you a log in /var/lib/mysql/ that may be helpful. Matomo-DB | Matomo-DB | The latest information about mariadb-install-db is available at Matomo-DB | https://mariadb.com/kb/en/installing-system-tables-mysql_install_db Matomo-DB | You can find the latest source at https://downloads.mariadb.org and Matomo-DB | the maria-discuss email list at https://launchpad.net/~maria-discuss Matomo-DB | Matomo-DB | Please check all of the above before submitting a bug report Matomo-DB | at https://mariadb.org/jira Matomo-DB | Matomo-DB exited with code 1
1
2023-12-29 2:43:11 0 [Note] InnoDB: IO Error: 5during write of 16384 bytes, for file ./matomodb/matomo_log_visit.ibd(16), returned 0
Docker - 运行 Mysql 容器后报错:[ERROR] –initialize specified but the data directory has files in it. Abort
1 2 3 4 5 6 7 8
2023-12-29 11:14:38+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 5.7.44-1.el7 started. 2023-12-29 11:14:39+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' 2023-12-29 11:14:39+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 5.7.44-1.el7 started. 2023-12-29 11:14:39+00:00 [Note] [Entrypoint]: Initializing database files 2023-12-29T11:14:39.612526Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details). 2023-12-29T11:14:39.615112Z 0 [ERROR] --initialize specified but the data directory has files in it. Aborting. 2023-12-29T11:14:39.615174Z 0 [ERROR] Aborting
拯救MaraDB;
1 2 3 4 5
2023-12-29 13:00:07+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' Matomo-DB | 2023-12-29 13:00:07+00:00 [Note] [Entrypoint]: Entrypoint script for MariaDB Server 1:11.2.2+maria~ubu2204 started. Matomo-DB | 2023-12-29 13:00:07+00:00 [Note] [Entrypoint]: Initializing database files
原来是docker-compose 运行maradb需要的权限 给mysql用户分配 执行权限!!
成功启动maradb!!next:无法运行matomo程序 You don’t have permission to access this resource.Server unable to read htaccess file, denying access to be safe
1 2 3
Matomo | [Fri Dec 29 21:28:33.351828 2023] [core:crit] [pid 53] (13)Permission denied: [client 172.21.0.1:5230] AH00529: /var/ www/html/.htaccess pcfg_openfile: unable to check htaccess file, ensure it is readable and that '/var/www/html/' is executable, re ferer: https://query.carlzeng.com/
unable to check htaccess file, ensure it is readable and that ‘/var/www/html/‘ is executable
How to clear the APT cache and delete everything from /var/cache/apt/archives/
The clean command clears out the local repository of retrieved package files. It removes everything but the lock file from /var/cache/apt/archives/ and /var/cache/apt/archives/partial/. The syntax is: sudo apt clean OR sudo apt-get clean
Delete all useless files from the APT cache
The syntax is as follows to delete /var/cache/apt/archives/: sudo apt autoclean OR sudo apt-get autoclean
#//yourls Docker启动修复 chown mysql /www/server/panel/data/compose/yourls_service/template/yMariaDb -R chown mysql /www/server/panel/data/compose/yourls_service/template/yourlsData20231229 -R
chmod +777 /www/server/panel/data/compose/yourls_service/template/yMariaDb -R chmod +777 /www/server/panel/data/compose/yourls_service/template/yourlsData20231229/ -R cd /www/server/panel/data/compose/yourls_service/template docker-compose down docker-compose up -d #//Matomo Docker启动修复 chmod +777 /www/server/panel/data/compose/matomo/matomo -R chmod +777 /www/server/panel/data/compose/matomo/matomodb -R chown mysql /www/server/panel/data/compose/matomo/matomo -R chown mysql /www/server/panel/data/compose/matomo/matomodb -R
cd /www/server/panel/data/compose/matomo docker-compose down docker-compose up -d #//Surveyking_mysql Docker启动修复 chmod +777 /www/server/panel/data/compose/surveyking/mysql_data -R cd /www/server/panel/data/compose/surveyking docker-compose down docker-compose up -d #//SRS cd /www/server/panel/data/compose/srs docker-compose down docker-compose up -d